Blog / Exploring Cop Data
I present Coppelgänger: a tool that shows you what NYPD cop a machine learning model thinks you most resemble. Find the cop lurking deep inside yourself by visiting coppelganger.lav.io, or read on for a description of my process.
Facial recognition systems are widespread, despite the growing body of work on the real and potential abuse of these systems (not to mention their general creep factor). These systems are typically deployed by government agencies, the police, and private companies, but basic facial recognition software is freely available to anyone who wishes to use it. I was curious how difficult it would be to make my own small facial recognition system using widely available tools. To do so, I plugged in a dataset of around 10,000 (publicly available) images of NYPD cops into a popular open source project called DeepFace.
Step 1: Get Some Data
Before I could make my system, I needed to collect some data about cops. At the very least I would need names and photos.
First attempt: NYC OpenData
I started by exploring data hosted by NYC OpenData. My first stop was the city payroll dataset, which contains details about every city employee. I was hoping to gather some cop names which might be useful later on. The payroll dataset does contain names, but it only goes up to 2023. I wanted something more current, so I moved on. But before I did, I got curious about how much money the NYPD was pulling in. OpenNYC has a pretty good interface for exploring data on their site, allowing users to sort, filter, and visualize datasets. You can even directly link to your data slices. Here’s cop payroll in 2023, sorted by overtime payments.

A wealthy cop
In 2023, cops were paid $864,406,530 in overtime, with 2,433 cops receiving $50,000 or more. A cop named John Moglia wins the top prize for overtime, pulling in $156,467.03 beyond his base salary.
Second Attempt: NYPD Personnel
The official NYPD site hosts a personnel roster of all NYPD cops, which, as far as I can tell, is up-to-date. They don’t provide any way of exporting the roster, but it is possible to scrape. The data gets loaded in a sort of unusual format, as column values without headers. You also have to manually iterate through the entire alphabet, and then paginate over the results. Here’s a quick script that downloads the entire dataset as as series of JSON files:
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:125.0) Gecko/20100101 Firefox/125.0",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "en-US,en;q=0.5",
"Referer": "https://oip.nypdonline.org/view/1004/@SearchName=SEARCH_FILTER_VALUE&@LastNameFirstLetter=A//%7B%22hideMobileMenu%22:true%7D/true/true",
"Connection": "keep-alive",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
}
letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
for letter in letters:
page = 1
while True:
try:
print("Getting page", page, "for letter", letter)
response = requests.get(
"https://oip.nypdonline.org/api/reports/2/datasource/serverList?aggregate=&filter=&group=&page="
+ str(page)
+ '&pageSize=100&platformFilters={"filters":[{"key":"@SearchName","label":"Search Name","values":["SEARCH_FILTER_VALUE"]},{"key":"@LastNameFirstLetter","label":"Last Name First Letter","values":["'
+ letter
+ '"]}]}&sort=',
headers=headers,
)
data = response.json()
people = data["Data"]
if len(people) == 0:
break
with open(f"{letter}_{page}.json", "w") as outfile:
json.dump(people, outfile)
page += 1
time.sleep(1)
except Exception as e:
print(e)
break
As it turns out, I did not end up using this dataset either! I did however run a quick analysis to determine what the most popular cop names are. The top cop name is Michael, accounting for 1084 cops, or 3.72% of the total cop population, with Christopher coming in at second place.
Top 25 Most Common NYPD Cop Names

- 1084 cops named Michael
- 674 cops named Christopher
- 609 cops named Joseph
- 564 cops named John
- 447 cops named Daniel
- 422 cops named Anthony
- 409 cops named Robert
- 404 cops named Matthew
- 390 cops named James
- 355 cops named Thomas
- 342 cops named Brian
- 307 cops named David
- 301 cops named Kevin
- 283 cops named Nicholas
- 268 cops named Steven
- 246 cops named William
- 244 cops named Jonathan
- 235 cops named Jason
- 223 cops named Andrew
- 222 cops named Jose
- 217 cops named Richard
- 208 cops named Ryan
- 181 cops named Patrick
- 170 cops named Sean
- 164 cops named Eric
Third and Final Attempt: 50-a.org
50-a.org is a wonderful searchable index of all complaints filed against NYPD officers. The site is named after a now-repealed law that was formerly used to hide police disciplinary records from the public. In addition to viewing disciplinary records for individual cops, the site also provides rosters for every precinct and command in the city. Some of these include photos.
I wrote a quick script to download all the images from the site (I tried to do this in a way that was slow and polite enough not to overwhelm their server), and ended up with around 11,000 images, or roughly 1/3 of NYPD cops.

Some pictures of cops
(Incidentally I also discovered that 50-a offers a csv file with the entire NPYD roster, making my previous scraping of the official roster totally pointless. Oh well!)
Part 2: Facial Recognition
As far as I’m aware there are two easy-to-use open source python libraries for facial recognition: face_recognition and DeepFace. Here I’ve opted for DeepFace which is more flexible and seems to be better maintained.
Basic DeepFace
To compare two faces in DeepFace, use the verify method:
from deepface import DeepFace
results = DeepFace.verify(img1_path="sam1.jpg", img2_path="sam2.jpg")
This will return a dictionary object looking something like this:
{'verified': True,
'distance': 0.6363782143676422,
'threshold': 0.68,
'model': 'VGG-Face',
'detector_backend': 'opencv',
'similarity_metric': 'cosine',
'facial_areas': {'img1': {'x': 510,
'y': 258,
'w': 426,
'h': 426,
'left_eye': (797, 424),
'right_eye': (634, 430)},
'img2': {'x': 145,
'y': 65,
'w': 315,
'h': 315,
'left_eye': (340, 192),
'right_eye': (243, 189)}},
'time': 0.24}
verified will be True if the faces seem to be from the same
person.
You can also easily compare a face to a folder full of images:
from deepface import DeepFace
results = DeepFace.find(
img_path = "sam1.jpg",
db_path = "/path/to/images"
)
In this second case, results will be a list containing potential matches.
Creating the system
Facial recognition is a three-part process: detection (finding the face-like pixels), embedding (or turning those pixels into a list of numbers), and comparison (calculating the distance between many lists of numbers).
Step 1: A face must be detected in an image. There are a bunch of machine learning models that can do this.

Finding face-like pixels
Step 2: The face is translated into a series of numbers (also called an “embedding”, or a vector) that represent different features of the face. There’s also a big bunch of machine learning models that can do this step.

Converting a face into numbers
Step 3: The embedding is compared to other embeddings to determine how similar one face is to another. This can be done with a few different techniques, like cosine similarity, which calculates the similarity in angles between two vectors, even if the length of the vectors is quite large. In this sense, facial recognition can be seen as a method for sorting lists. If you want to learn more about how this works, here’s a nice explanation.
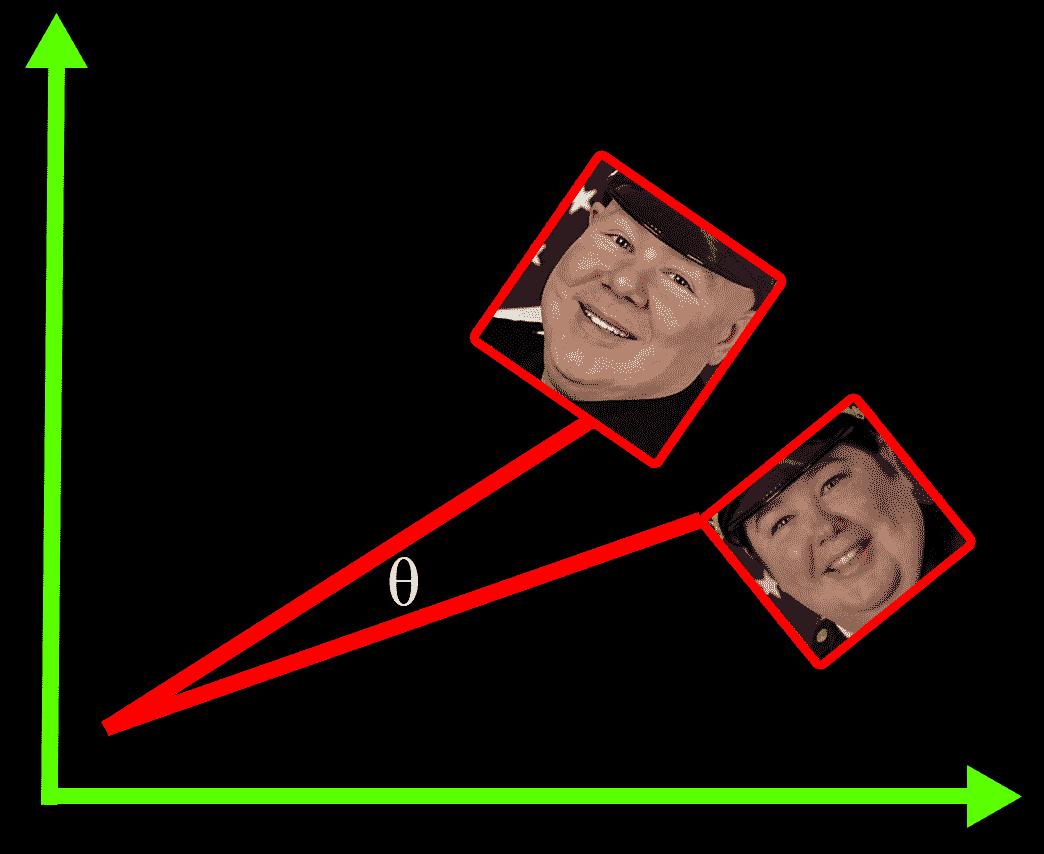
Comparing lists of numbers with cosine similarity
DeepFace is a wrapper for many other open source face detection and embedding systems.
This makes it easy to mix and match different face detection and recognition models
needed for steps 1 and 2. Each model has its own trade-offs in terms of speed and
accuracy, with faster models being typically less accurate. According to
DeepFace’s
benchmarks
using the retinaface detection model with the
Facenet512 recognition model yields the most accurate results. In my
experiments I noticed this combination was a bit slow on shared hardware, so I swapped
retinaface for yunet.
After a face is detected and converted into a numeric representation, it needs to be compared to an existing database of faces. Although there’s a built-in way to do this in DeepFace, I found their system a bit slow. Instead I decided to use Voyager, a quick vector search library from Spotify. Voyager is an “approximate nearest-neighbor” search library. This means it prioritizes speed over accuracy – it returns results that are approximately correct. It also only stores vectors (with a numerical id) so I need to store the other cop data (like names & badge numbers) in a separate file.
Here’s a slightly simplified version of the script that generates my system. It loads up a JSON file of cop data, then iterates through it and tries to create a facial embedding for each cop image. If it fails to find a face in the image (which does happen!) it passes over that cop entirely. It then saves the index of all the embeddings to disk, as well as a new JSON file that only contains cop data for cops that were successfully processed by the system.
import json
from deepface import DeepFace
import os
from voyager import Index, Space
out = []
# load in the cops from 50a
with open("./50a_cops.json") as infile:
cop_data = json.load(infile)
# FaceNet512 returns a vector that's 512 items long
dims = 512
index = Index(Space.Cosine, num_dimensions=dims)
for c in cop_data:
try:
# create a face embedding using Facenet512, yunet, and don't align the face
embedding = DeepFace.represent(
c["img"], detector_backend="yunet", model_name="Facenet512", align=False
)
# add the embedding to voyager
index.add_item(embedding[0]["embedding"])
# add other cop data to the final output
out.append(c)
except Exception as e:
# if we get an error, print the error and skip over this cop
print(e)
print("Failed to find embeddings for", c)
continue
# save our voyager index to disk
index.save("cop_embeddings.voy")
# save our filtered down cop db to disk
with open("final_bosses.json", "w") as outfile:
json.dump(out, outfile, indent=2)
Then, to query an image, we use DeepFace to generate embeddings for that image, and then search the Voyager index with them:
import json
from deepface import DeepFace
from voyager import Index
input_image = "SOME_IMAGE.jpg"
# load our saved database of cop embeddings
copindex = Index.load("./cop_embeddings.voy")
# load the cop data
with open("./final_bosses.json") as infile:
cops = json.load(infile)
# convert the input image to an embedding
result = DeepFace.represent(
input_image, detector_backend="yunet", model_name="Facenet512", align=False
)
embedding = result[0]["embedding"]
# search voyager for our embedding. it returns the top 3 closest matches
neighbors, dists = copindex.query(embedding, k=3)
# list the top three closest matches
# the id stored in voyager is just the index in our list of cops
# dist is a numerical distance between the search image and the result image
for id, dist in zip(neighbors, dists):
cop = cops[id]
print(cop["name"], cop["badge"], dist, cop["img"])
The system has a number of limitations. In general, I’ve chosen speed over accuracy in order to run the system cheaply as a website: I’m using a face detection model that’s not the most accurate, especially if the subject isn’t facing the camera, and I’m using Voyager which further limits the accuracy. The system also only has around 30% of New York cops in it, making it not particularly useful for identifying cops, and more useful getting a sense of how these types of systems work by means of finding your very own cop doppelgänger (or coppelgänger).
With that in mind, if you want to see what cops you (maybe) resemble, just visit: https://coppelganger.lav.io.
Part 3: Sorting Cops by How Similar They Are to Each Other
After generating embeddings for each cop, it became possible to compare every cop to eveäry other cop.
Here for example are some small clusters of similar looking cops, according to Facenet512. To make these, the system picks a random cop, then finds the cop most similar to that first cop, then the cop most similar to the second cop, and so on.

Coppelgänger cluster 1

Coppelgänger cluster 2

Coppelgänger cluster 3

Coppelgänger cluster 4

Coppelgänger cluster 5

Coppelgänger cluster 6

Coppelgänger cluster 7
I hope these cops enjoy their own coppelgängers!
Part 4: Emotion Analysis
I conclude with a brief exploration of cop facial sentiment. While automated emotion and sentiment analyses are always a bad idea, let’s give it a go anyway since DeepFace has a built-in facial sentiment analyzer, claiming to be able to recognize emotions like happiness, anger, sadness and disgust.
The angriest cops in New York
I can, in fact, sense a bit of anger.

The most disgusted (not disgusting) cops in New York
Maybe – I’m on the fence here if any of these cops look disgusted.

The happiest cops in New York.
These cop faces actually do look very happy!

The saddest cops in New York?
With one exception I really don’t see the sadness here. Most of these cops look
normal, happy even.

Maybe it’s a sadness lurking deep behind the eyes?

Melancholy that only the machine can perceive.