Blog / Reducing 'Avatar 2: Way of the Water' to One Dimension
Last night, my shared studio/art space LARPA held the inaugural screening of what we hope will become a regular event: High Concept Low Effort Cinema.
For our first ever production, Claire Hentschker and I attempted to reduce the overly-dimensional film “Avatar 2: Way of the Water” into a single dimension. Here are the results (turn subtitles on for the complete experience):
Had to use Vimeo because YouTube insta-blocked it
How to reduce a film into a single dimension
What does it mean to reduce a film to a single dimensions?
Regular 2D film is already at least a three-dimensional medium: there are two dimensions of space, and one of time. This doesn’t count audio of course, which arguably adds one (or more) dimensions of content to the mix. And then there are subtitle files and captions too. All together a typical digital video file might occupy six dimensions of content space!
N-Dimensional Content Space -> |, where N equals 'navi'
Our goal, therefore, was not to reduce the film to a single dimension in a literal sense, but to isolate its different component parts (visual, audio, subtitles), make our best low-effort attempt to reduce their dimensionality, and then stick everything back together to form a new whole.
1D
Visuals
First we need to find a way to reduce the visual dimensions of the film. Avatar 2 is a 3D movie that uses cutting edge technology to create a highly immersive cinematic experience. Fortunately, we were only able to get our hands on a 2D version. This immediately removed one of the unnecessary dimensions.
To remove next unnecessary dimension, we began by shrinking the video into a single vertical line using ffmpeg:
ffmpeg -i avatar2.mp4 -vf "scale=1:1080" line.mp4
This doesn’t work, however, because H.264 can’t output video with odd-numbered dimensions, which sadly includes the number 1.
So, already we must make an artistic compromise! Let’s try again, but this time shrink the video to 2 pixels wide:
ffmpeg -i avatar2.mp4 -vf "scale=2:1080" line.mp4
This manages to output a seemingly valid video file, but it immediately crashed VLC player. Next up, we tried to letterbox the video, adding padding to the left and right of the vertical line.
# The -filter_complex argument lets us pass the output of the scaled filter to the padding filter
ffmpeg -i avatar2.mp4 -filter_complex "[0]scale=2:1080[1];[1]pad=1920:1080:960:0:black" -aspect 1920:1080 line.mp4
It works (once we added the -aspect flag).
However, a 2-pixel strip is quite hostile to the audience (particularly for a movie that runs over three hours long), and initial test screening results were poor. There comes a time in every artistic endeavour where you are forced balance the integrity of your vision against questions of legibility and popular appeal. So, we decided to shrink everything down to a single pixel strip, then expand it back out to a more crowd-pleasing 60 pixels.
# Here we scale to 1, then to 60, then pad
ffmpeg -i avatar2.mp4 -filter_complex "[0]scale=1:1080[1];[1]scale=60:1080[2];[2]pad=1920:1080:930:0:black" -aspect 1920:1080 line.mp4
Audio
How do you reduce the dimensions of an audio file?
We considered adding high or low pass filters and other effects to remove frequencies, without any notable results. Then we tried a similar technique to how we handled/tortured the visuals: shrinking, then expanding.
First we sped up the audio track 10x with ffmpeg:
ffmpeg -i avatar2.mp3 -af atempo=10.0 avatar2_fast.wav
And then used the paulstretch library to stretch it back out to the original length:
python paulstretch_stereo.py --stretch=10 avatar2_fast.wav avatar2.wav
This yielded interesting results, and partially met our dimension-reducing imperative.
But there are many ways to collapse multiple things into a single thing, and Claire came up with a much better idea: to reduce the dimensions of the audio track by giving every character in the film the same voice. To accomplish this we first divided the film into 20 segments, each 10 minutes long:
ffmpeg -i avatar2.mp4 -c copy -ap 0 -segment_time 00:10:00 -f segment parts/part_%03d.mp4
Claire then uploaded the chunks, one at a time, to TikTok, applied the “Townie” voice filter to each one, and then exported the resulting files back to her computer.
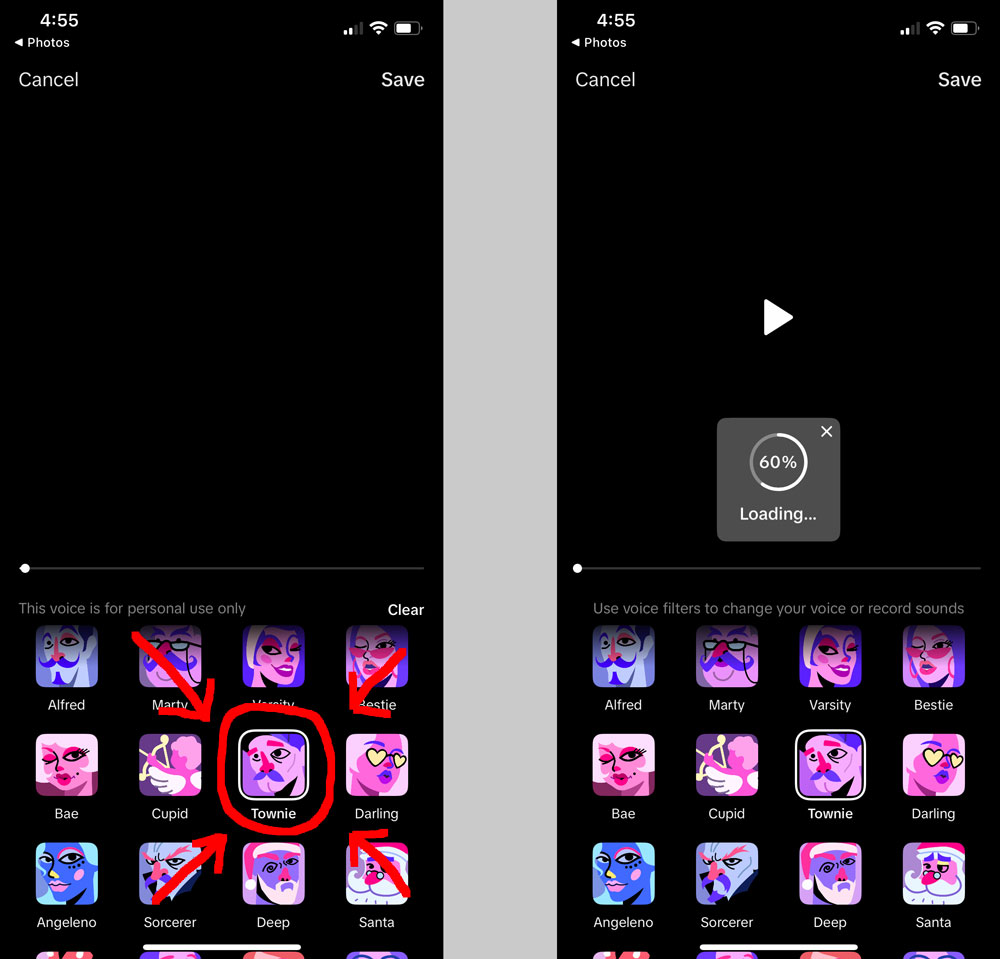
The media pipeline
This turned out to be one of the most effortful steps of the entire low-effort process.
We then recombined the files and replaced the audio track in the original film:
# create a list of all the mp4 files in the directory
for f in part*.mp4 ; do echo file \'$f\' >> list.txt; done
# concatenate them
ffmpeg -f concat -safe 0 -i list.txt -c copy one_d_audio.mp3
# replace the original audio with the new one
ffmpeg -i avatar2.mp4 -i one_d_audio.mp3 -c:v copy -map 0:v:0 -map 1:a:0 avatar2_better_audio.mp4
Now every character is doing an impression of Ray Liotta in Goodfellas. Perfection.
Subtitles
Finally, the subtitles. What does it mean to reduce the dimensions of a text? Inspired by the work of Allison Parrish, we decided to explore the possibilities of word vectors as means to “average” out written language.
Using spaCy, we extracted word vectors from each line in the subtitle file. Per spaCy’s docs, word vectors from multiple tokens are automatically averaged. We then replace that line in the subtitle file with the most similar word from the entire corpus.
I’m positive that was not the best approach.
from pysubparser import parser, writer
import spacy
import re
nlp = spacy.load("en_core_web_lg")
def most_similar(everything, token):
'''find the most similar word to given line of text'''
scores = []
for t in everything:
if t.is_stop:
continue
scores.append((t.similarity(token), t.text))
scores = sorted(scores, key=lambda k: k[0], reverse=True)
return scores[0]
def get_all():
'''grab all the words and stick them in a spacy doc'''
subtitles = parser.parse('./avatar2.srt')
words = []
all_text = ' '.join([s.text.strip() for s in subtitles]).lower()
all_text = re.sub(r'[^a-z ]', '', all_text)
all_text = ' '.join(list(set(all_text.split(' '))))
all_text = nlp(all_text)
return all_text
def main():
out = []
all_text = get_all()
subtitles = parser.parse('./avatar2.srt')
for i, s in enumerate(subtitles):
text = s.text
doc = nlp(text)
average = most_similar(all_text, doc)
s.lines = [average[1]]
out.append(s)
writer.write(out, 'average_subtitles.srt')
main()
The results:

Clearly room for improvement here. Nonetheless, the dimension-collapsing experiment is concluded.